
引言
Gridea Pro 是一款基于 Wails 框架构建的桌面端静态博客管理工具。用户在本地编辑文章、配置主题,系统将全部内容渲染为静态 HTML 后部署到 GitHub Pages、Gitee Pages 或 Vercel 等托管平台。
这套系统在工程上面临一个有趣的矛盾:它是一个桌面应用,数据持久化在本地 JSON 文件中,没有传统意义上的数据库;但它又包含一个完整的静态站点生成器 (SSG),需要处理模板编译、资源管线、SEO 元数据生成等服务端才会遇到的问题。如何在一个进程内同时容纳「内容管理」和「站点构建」两套截然不同的子系统,是 Gridea Pro 后端架构设计的核心命题。
本文将从分层结构、领域建模、泛型持久化、多引擎渲染、插件化扩展等五个维度,深入分析 Gridea Pro 后端的架构设计思路与实现细节。
一、分层架构:四层边界,单向依赖
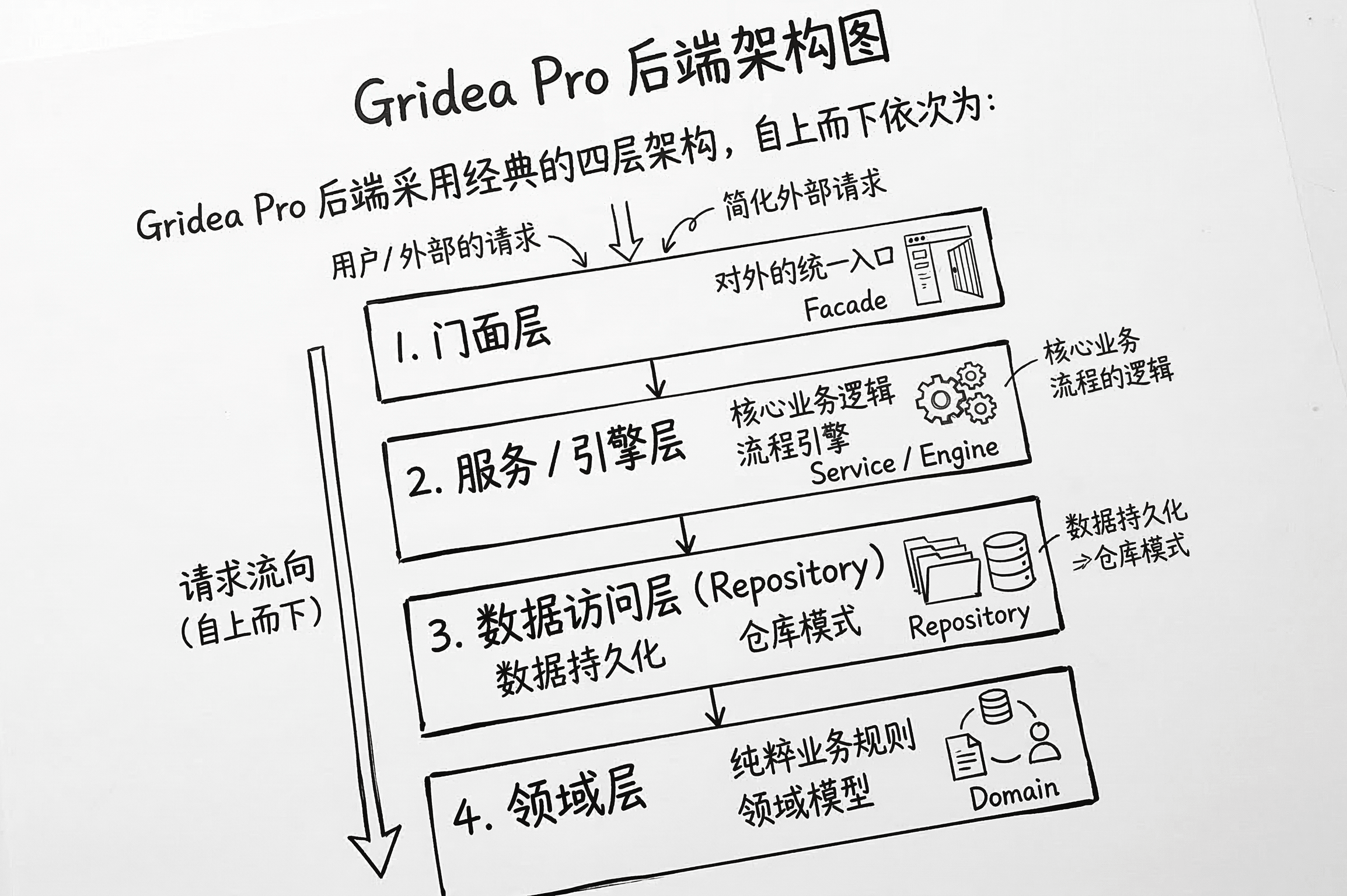
Gridea Pro 后端采用经典的四层架构,自上而下依次为:
Facade → Service / Engine → Repository → Domain
每一层只允许依赖其下方的层,绝不反向引用。这四层并非照搬 Web 后端的教科书定义,而是根据桌面 SSG 应用的特性做了针对性的裁剪。
Facade:前端的唯一入口
Wails 框架要求将 Go 结构体绑定到前端 JavaScript 上下文中,Facade 层正是为此而设。每个 Facade(如 PostFacade、RendererFacade)都是一个极薄的包装器,内部持有对应 Service 的指针,职责仅限于:
- 获取 Wails 上下文(
WailsContext) - 调用 Service 方法
- 返回结果
type RendererFacade struct {
internal *engine.Engine
}
func (f *RendererFacade) RenderAll() error {
ctx := WailsContext
if ctx == nil {
ctx = context.TODO()
}
return f.internal.RenderAll(ctx)
}
这种设计的价值在于隔离框架耦合。Service 层完全不知道 Wails 的存在,它只接受标准的 context.Context。如果未来需要将 Gridea Pro 改造为 CLI 工具或 Web 服务,只需替换 Facade 层即可——事实上,项目中的 MCP Server(Model Context Protocol,用于 AI 工具集成)就是另一套独立的「Facade」,它直接创建 Service 和 Engine 实例,完全绕过 Wails:
// mcp/server.go — 独立于 Wails 的另一条初始化路径
func initServices(appDir string) *Services {
rendererService := engine.New(appDir, postRepo, themeRepo, settingRepo)
// ...
}
同一套业务逻辑,两种接入方式,零代码重复。这就是 Facade 层存在的意义。
Service 与 Engine:业务逻辑的两极
internal/service/ 和 internal/engine/ 是系统中最厚重的两层,但它们的职责截然不同:
-
Service(14 个文件):处理 CRUD 业务逻辑。
PostService负责文章的创建、更新、删除和查询;TagService管理标签的增删改;DeployService协调部署流程。它们的共同特征是围绕实体的生命周期展开操作。 -
Engine(9 个文件):驱动静态站点生成。
TemplateDataBuilder将领域数据转换为模板视图;PageRenderer调用模板引擎渲染 HTML;SeoGenerator生成 RSS、Sitemap;AssetManager编译 LESS、复制静态资源。它们的共同特征是围绕一次完整的构建流程协同工作。
这两个包之间存在一条单向依赖:DeployService 持有 *engine.Engine 的引用,用于在部署前触发站点重建。反过来,Engine 对 Service 一无所知。
这种拆分并非简单的文件整理。它解决了一个真实的工程问题:当渲染相关代码与 CRUD 代码同属 package service 时,渲染模块的内部类型(RSS XML 结构体、Sitemap 结构体、搜索索引条目)和常量(DirOutput、DefaultPostPath)会暴露在 Service 包的公共命名空间中。任何同包文件都可以随意引用它们,依赖关系在包内部悄然蔓延,直到有一天你发现修改一个 RSS 字段名会导致三个毫不相关的 Service 编译失败。将 Engine 独立成包后,这些类型被封装在 package engine 的边界内,包外只能看到 engine.Engine 这一个公开入口。
Repository 与 Domain:数据的根基
Domain 层定义纯粹的领域模型和接口,不包含任何实现细节。Repository 层实现数据持久化。这两层的设计将在后续章节展开。
二、领域建模:在「够用」与「正确」之间取平衡
internal/domain/ 是整个系统中依赖数最少的包——它只依赖 Go 标准库。所有上层包都依赖它,但它不依赖任何业务包。这种「只被依赖,不依赖别人」的地位使其成为系统的稳定锚点。
Domain 层包含两类定义:
实体结构体,如 Post、Tag、Category、Memo 等,它们携带业务校验逻辑:
type Post struct {
ID string `json:"id"`
Title string `json:"title"`
CreatedAt time.Time `json:"createdAt"`
Content string `json:"content"`
FileName string `json:"fileName"`
Tags []string `json:"tags"`
CategoryIDs []string `json:"categoryIds"`
Published bool `json:"published"`
// ...
}
func (p *Post) Validate() error {
if strings.TrimSpace(p.Title) == "" {
return errors.New("title is required")
}
// ...
}
仓库接口,如 PostRepository、TagRepository,它们为上层定义数据访问的契约:
type PostRepository interface {
Create(ctx context.Context, post *Post) error
Update(ctx context.Context, post *Post) error
Delete(ctx context.Context, fileName string) error
List(ctx context.Context, page, size int) ([]Post, int64, error)
// ...
}
值得注意的是 Identifiable 接口:
type Identifiable interface {
GetID() string
}
这个看似简单的接口是泛型仓库系统的基石,我们将在下一节看到它如何消除大量重复代码。
Domain 层还承载了一个微妙的设计决策:ThemeConfig 与 ThemeConfigSchema 的区分。前者是用户在站点设置中填写的配置值(站点名、文章路径、分页大小),后者是主题 config.json 的元数据定义(字段名、类型、默认值、可选项)。两者都与「主题配置」有关,但语义完全不同——一个描述「值」,一个描述「值的结构」。通过精确命名将它们安置在同一个包中,既避免了为一个文件单独建包的过度设计,又防止了命名冲突带来的混淆。
三、泛型持久化:用类型参数消灭重复
Gridea Pro 的数据存储在本地 JSON 文件中(config/tags.json、config/menus.json 等),每个文件的结构都是 { "rootKey": [...] } 的形式。如果为每种实体各写一个 Repository,会出现大量结构相同的 CRUD 代码。
BaseJSONRepository[T domain.Identifiable] 利用 Go 1.18+ 的泛型特性,将这些重复逻辑抽取为一个通用基类:
type BaseJSONRepository[T domain.Identifiable] struct {
mu sync.RWMutex
appDir string
fileName string
rootKey string
data []T
loaded bool
}
它提供了完整的 CRUD 操作——List、Get、Add、Update、Delete、SaveAll——以及两个关键的基础设施能力:
延迟加载与双重检查锁:数据不在构造时立即读取,而是在第一次访问时通过 initIfNeeded() 触发加载。为了在并发场景下避免重复加载,采用了经典的 Double-Checked Locking 模式——先用读锁检查 loaded 标志,若未加载则升级为写锁并再次检查:
func (r *BaseJSONRepository[T]) initIfNeeded() error {
r.mu.RLock()
if r.loaded {
r.mu.RUnlock()
return nil
}
r.mu.RUnlock()
return r.forceLoad() // 内部持有写锁,二次检查 loaded
}
Copy-on-Write 更新策略:每次写操作都会先构建新的数据切片,尝试写入磁盘,只有磁盘写入成功后才更新内存缓存。如果磁盘写入失败,内存状态自动回滚:
func (r *BaseJSONRepository[T]) Update(ctx context.Context, id string, item T) error {
// ...
newData := make([]T, len(r.data))
copy(newData, r.data)
newData[idx] = item
originalData := r.data
r.data = newData
if err := r.save(); err != nil {
r.data = originalData // 回滚
return err
}
return nil
}
这套设计将「如何读写 JSON 文件」和「如何保证并发安全」的复杂性封装在一处。具体的 Repository 实现极其简洁——TagRepository、MenuRepository、LinkRepository 等几乎只需声明类型参数和文件路径,就获得了全套线程安全的 CRUD 能力。
四、多引擎渲染:工厂模式与策略模式的联合应用
Gridea Pro 支持三种模板引擎——Go Template、EJS、Jinja2。不同的主题可能使用不同的引擎,系统需要在运行时根据主题配置动态选择。
这通过 ThemeRenderer 接口和 RendererFactory 工厂类实现:
// render/renderer.go
type ThemeRenderer interface {
Render(templateName string, data *template.TemplateData) (string, error)
GetEngineType() string
ClearCache()
}
// render/factory.go
func (f *RendererFactory) CreateRenderer() (ThemeRenderer, error) {
engineType, _ := f.detectEngineType()
switch engineType {
case "gotemplate":
return NewGoTemplateRenderer(f.config), nil
case "ejs":
return NewEjsRenderer(f.config), nil
case "jinja2":
return NewJinja2Renderer(f.config), nil
}
}
引擎检测逻辑有两级优先级:首先读取主题 config.json 中显式声明的 engine 字段;若未声明,则扫描 templates/ 目录下的文件扩展名(.ejs、.jinja2、.html)自动推断。这种「约定优于配置 + 显式配置优先」的策略,既降低了主题开发者的认知成本,又保留了精确控制的能力。
从 Engine 层的视角看,engine.Engine 完全不关心底层用的是哪种模板引擎。它只通过 ThemeRenderer 接口与渲染器交互。当用户切换主题时,SetTheme() 方法创建新的渲染器实例并注入 PageRenderer:
func (s *Engine) SetTheme(themeName string) error {
if s.renderer != nil && s.currentTheme == themeName {
return nil // 缓存命中,跳过重建
}
factory := render.NewRendererFactory(s.appDir, themeName)
renderer, _ := factory.CreateRenderer()
s.renderer = renderer
s.pageRenderer.SetRenderer(renderer)
// ...
}
这里有一个细微但重要的性能优化:主题渲染器被缓存在 Engine 实例上,只有当主题名称发生变化时才重建。对于用户在编辑器中频繁保存触发预览重建的场景,这避免了每次都重新解析模板文件。
五、Engine 内部:组合优于继承的实践
Engine 的内部结构是本架构中最值得细说的部分。它由五个独立的协作者组成,每个协作者只持有自己需要的最小依赖集:
| 协作者 | 职责 | 核心依赖 |
|---|---|---|
TemplateDataBuilder |
将 Domain 实体转换为模板视图数据 | 各 Repository 接口 |
PageRenderer |
调用模板引擎渲染 HTML 并写入文件系统 | ThemeRenderer 接口 |
SeoGenerator |
生成 RSS 2.0、Sitemap XML、Robots.txt | 无外部依赖 |
SearchIndexBuilder |
生成搜索索引 JSON(含 HTML 转纯文本) | 无外部依赖 |
AssetManager |
静态资源复制、LESS 编译、样式覆盖注入 | ThemeConfigService |
Engine 本身退化为一个薄薄的协调层,它的 RenderAll() 方法实质上是一个编排器——按正确的顺序调用各协作者,并合理利用并发:
RenderAll 执行流程:
┌─────────────────────────────────────────────────────────┐
│ 1. AssetManager: 复制主题资源 + 站点静态资源 (串行) │
│ 2. TemplateDataBuilder: 构建全量模板数据 (串行) │
│ 3. PageRenderer: 渲染列表类页面 (串行,因共享分页状态) │
│ 4. PageRenderer: 渲染文章详情页 (并发,runtime.NumCPU) │
│ 5. 独立任务并发执行 (errgroup, limit=10): │
│ ├── PageRenderer: 友链页、闪念页、404 页 │
│ ├── SearchIndexBuilder: search.json │
│ └── SeoGenerator: feed.xml, sitemap.xml, robots.txt │
└─────────────────────────────────────────────────────────┘
这种拆分带来了三个具体的工程收益:
依赖最小化。SeoGenerator 和 SearchIndexBuilder 没有任何外部依赖,它们接收一个 *template.TemplateData 指针就能完成全部工作。这意味着它们可以在完全隔离的环境中进行单元测试,不需要 mock 任何 Repository 或渲染器。
并发安全性。文章详情页的并发渲染使用 errgroup 配合 runtime.NumCPU() 限流。由于每篇文章的渲染是独立的(各自创建 postData 副本,互不共享状态),并发在这里是安全且高效的。而列表类页面(首页、归档页)因为涉及分页状态的连续计算,仍然保持串行执行——架构设计中,知道哪里不该并发和知道哪里该并发同样重要。
容错降级。PageRenderer 内置了 fallback 机制:当主题模板渲染失败时(比如用户切换到一个模板语法有误的主题),系统不会崩溃,而是自动回退到内置的简单 HTML 模板,确保站点至少能展示基本内容。这是 PageRenderer 独立存在的另一个理由——降级逻辑与正常渲染逻辑紧密相关,但与 SEO 生成或搜索索引构建毫无关系。
六、插件化扩展点:评论与部署
系统中有两个维度需要支持多种第三方服务:评论系统和部署平台。它们采用了相同的设计模式——接口 + 工厂——但落地方式略有差异。
部署:策略模式
deploy.Provider 接口极其简洁:
type Provider interface {
Deploy(ctx context.Context, outputDir string, setting *domain.Setting, logger LogFunc) error
}
DeployService 根据用户配��的平台类型(github、gitee、vercel)实例化对应的 Provider。值得注意的是 LogFunc 回调的设计:部署过程需要实时向前端推送日志,但 deploy 包不应该知道 Wails 的 runtime.EventsEmit API。通过将日志输出抽象为一个函数签名,deploy 包彻底切断了对 UI 框架的依赖。
评论:工厂模式 + 基类复用
评论系统的复杂度更高——7 种平台(Valine、Waline、Twikoo、Gitalk、Giscus、Disqus、Cusdis),每种都有不同的 API 认证方式和数据格式。comment 包通过 BaseProvider 基类提供共享的 HTTP 客户端配置、超时控制、JSON 序列化和错误分类:
type BaseProvider struct {
client *http.Client
logger *slog.Logger
}
各具体 Provider(如 ValineProvider、WalineProvider)嵌入 BaseProvider,只需实现差异化的 API 调用逻辑。工厂函数 NewProvider() 根据配置分发到正确的实现。
这种设计使得新增一个评论平台的成本极低:实现 domain.CommentProvider 接口,在工厂函数中添加一个 case 分支,就完成了。已有平台的代码完全不受影响。
七、数据流全景:从编辑到部署
综合以上所有层次,我们可以勾勒出一次完整的「编辑 → 渲染 → 部署」数据流:
用户在前端编辑文章并保存
↓
PostFacade.Save() [Facade 层]
↓
PostService.Update() [Service 层]
↓
PostRepository.Update() → 写入 posts/*.md [Repository 层]
↓
用户点击「发布」
↓
DeployFacade.Deploy() [Facade 层]
↓
DeployService.DeployToRemote() [Service 层]
├── engine.Engine.RenderAll() [Engine 层]
│ ├── TemplateDataBuilder.Build() → 读取所有 Repository
│ ├── PageRenderer.RenderIndex/Post/... → 调用 ThemeRenderer
│ ├── SeoGenerator.RenderRSS/Sitemap → 生成 XML
│ ├── SearchIndexBuilder.RenderSearchJSON → 生成 JSON
│ └── AssetManager.CopyThemeAssets → LESS 编译 + 文件复制
↓
deploy.GitProvider.Deploy() [Deploy 层]
→ git add, commit, push 到远程仓库
每一层都只做自己该做的事。Facade 不知道文件怎么存储,Service 不知道模板怎么渲染,Engine 不知道代码怎么部署。信息沿着分层边界单向流动,每一层向上层屏蔽了自己的实现细节。
结语
Gridea Pro 的后端架构没有使用任何花哨的框架或复杂的中间件。它的设计原则可以归结为几句话:
- 让包的边界对齐领域的边界——CRUD 是业务逻辑,SSG 是构建引擎,它们属于不同的包。
- 依赖指向稳定——所有箭头都指向 Domain 层,Domain 不依赖任何人。
- 用接口隔离变化——模板引擎会变、评论平台会变、部署方式会变,但接口不变。
- 在正确的粒度复用——泛型仓库消灭了 CRUD 重复,
BaseProvider消灭了 HTTP 重复,但没有过度抽象到让人看不懂的地步。
这些原则并不新鲜,但将它们一致地落实到一个真实项目的每一个角落——从一行 GetID() 接口定义到一整个并发渲染编排流程——才是架构设计真正的挑战所在。
评论